 7 min read
7 min read #01. 안드로이드 구조 - MVVM & MVI, Clean Architecture
목차15
개요
SW 구조에 대해 공부하다보면 한번씩 들어봤을 Clean Architecture, 그리고 안드로이드 앱 개발을 공부하다보면 항상 들리는 MVVM & MVI 패턴.
여러 프로젝트를 하면서 이 구조가 무엇인지 경험적으로는 받아들였으나, 시간을 들여서 진득하게 정리해본 기억이 없어, 이참에 정리해보고자 한다.
MVVM vs MVI
MVVM : Model - View - ViewModel
- Model: 데이터 모델
- View: 화면에 보여줄 화면, 그리고 UI
- ViewModel: View와 Model 사이에 위치하 비즈니스 로직을 처리하는 모듈
예를 들어, ‘사용자 프로필 정보’를 보여주는 화면이 있다고 가정해보자. 이 화면에는 다음의 내용과 기능이 필요할 것이다:
- [데이터] 사용자 정보 (이름, 이메일 주소, 프로필 이미지 등)
- [편집] 사용자 정보 수정
- [조회-로컬] 기기 내에 저장된 사용자 정보 불러오기
- [조회-통신] 혹은, 서버로부터 사용자 정보 받아오기 …
그렇다고 위의 모든 로직을 UI 레이어에 포함할 수는 없다.
UI 본연의 목적은 **“사용자가 원하는 정보를 그려주는 것”**이지, DB 조회나 서버와의 통신이 아니기 때문이다.
이를 위해 UI와 data source 사이에 ViewModel이라는 중간 지대를 두어 비즈니스 로직을 처리하고, UI 는 데이터를 표시하는 본연의 역할에 집중할 수 있는 것이다.
이를 구조화된 코드로 보자면 아래와 같다:
class UserViewModel : ViewModel() {
val userInfo = MutableStateFlow<UserInfo>(UserInfo.empty())
val isLoading = MutableStateFlow(false)
val errorMessage = MutableStateFlow<String?>(null)
val isRefreshing = MutableStateFlow(false)
// 비즈니스 로직
fun loadUserInfo() { ... }
fun refresh() { ... }
}// UI Layer의 어느 UI
val userInfo by viewModel.userInfo.collectAsStateWithLifecycle()
val isLoading by viewModel.isLoading.collectAsStateWithLifecycle()
val error by viewModel.errorMessage.collectAsStateWithLifecycle()비즈니스 로직은 모두 ViewModel에서 전담하고, UI는 ViewModel이 관리하는 data만 구독해서 받아쓰는 방식이다.
MVI : Model - View - Intent
그러나 기존의 MVVM은 상태 관리의 복잡성, View와 ViewModel의 다중 단방향/양방향 통신이라는 문제가 있었다.
예를 들어, isLoading = false라고 해서 로딩이 성공적으로 끝났음을 보장할 수 없다. 로딩이 성공적으로 끝난 상태인건지 실패한 것인지 errorMessage를 보고 판단하거나 실제 userInfo에 제대로 된 값이 있는지를 함께 봐야 알 수 있다.
즉, “지금 화면이 어떤 상태인가?”를 한눈에 보기 힘들고, 변수의 상태에 따라서 무수히 많은 상태 조합이 발생할 수 있지만 구조적으로 이를 막을 수가 없었다.
이러한 상태 관리의 복잡도를 줄이기 위해, MVVM 패턴에 MVI는 3가지 구조적인 제약을 추가하였다.
1. State: View는 단일 State 객체 하나만 구독한다.
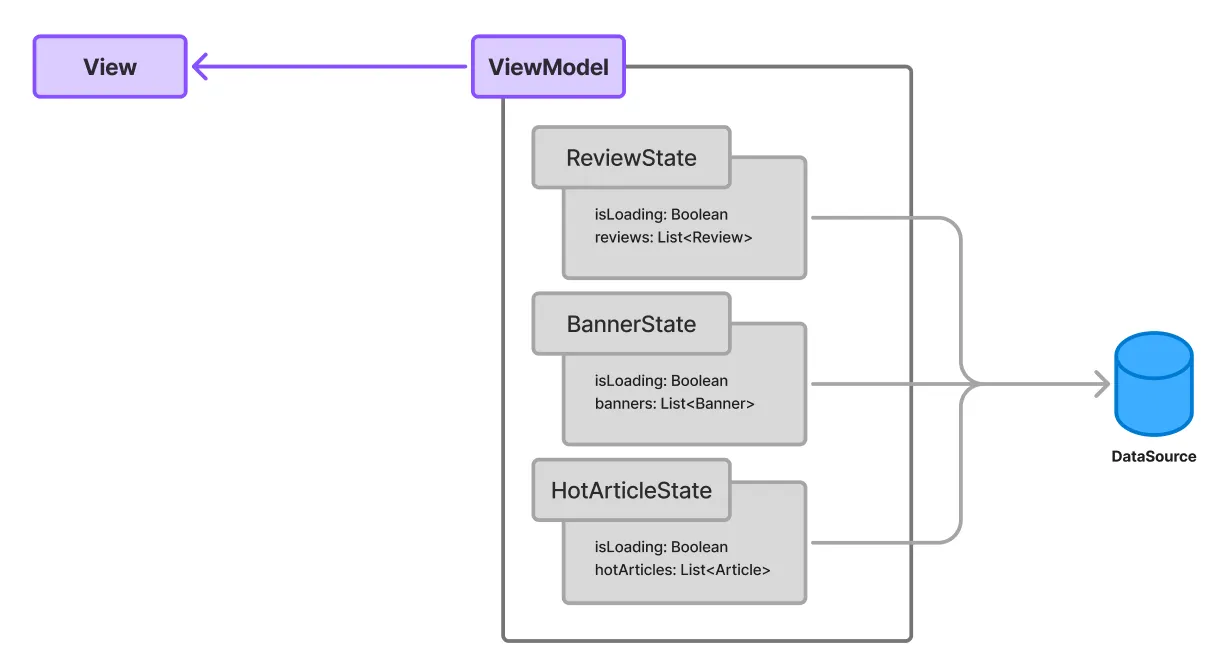
이상적인 MVI 코드에서는, 모든 데이터와 상태가 하나의 단일 state로 묶여서 전달된다. 예를 들어 홈 화면에서 사용자의 리뷰, 광고 배너, 인기 게시글을 노출해야하는 상황에서는:
data class HomeState(
// SectionLoadState는 Init/Loading/Success/Error 등의 값을 가짐
val reviewState: SectionLoadState, // 리뷰 섹션
val bannerState: SectionLoadState, // 배너 섹션
val hotArticleState: SectionLoadState, // 핫 게시글 섹션
val reviews: List<Review>, // 실제 데이터
val banners: List<Banner>,
val hotArticles: List<Post>
)위와 같이 로딩 상태, 데이터, 에러가 하나의 객체로 묶이게 되므로,
val state by viewModel.state.collectAsStateWithLifecycle()View에서는 하나의 state만 구독하여도 모든 상태를 추적할 수 있다.
물론 이 구조의 경우, 만약 reviewState와 hotArticleState이 독립적인 소스로부터 데이터를 불러오게 된다면, reviewState의 값이 나중에 변경되었다는 이유로 불필요한 recomposition이 발생할 수 있다.
따라서 나는 위와 같은 독립적인 data stream을 갖는 경우에는, 각 도메인이나 섹션별로 State를 구분하여, 여러 state를 구독하는 하이브리드 방식을 사용하고 있다.
2. Intent: View는 ViewModel의 메서드를 직접 호출하지 않고, 사용자의 Intent를 보낸다.
3. Effects: ViewModel은 View에게 직접 간섭하지 않고(Callback X), Event를 발생시켜 구독중인 View의 변화를 유도한다.
intent는 사전적인 의미로 ‘의지’ 라는 뜻이다. 여기서는 ‘앱의 상태를 바꾸려는 사용자의 의도나 액션’ 정도로 생각할 수 있다.
예를 들어 새로고침 버튼을 누르거나 이전 버튼을 누르는 행위는, 사용자가 갱신된 데이터를 확인하거나 이전 화면으로 이동(혹은 작업을 취소)하겠다는 ‘의도’이다.
event는 pub-sub 관계를 따르며, ViewModel이 발행하고, View는 관찰하는 이벤트가 발행되면 적절한 액션을 취할 수 있다. 즉, 둘 모두 View와 ViewModel이 직접 상호작용하는 대신 메시지를 중개하는 중간책을 두는 느낌이다.
결론적으로 View는 ViewModel의 특정 기능을 이용하거나 요청하기 위해 Intent를 보내고, ViewModel은 Intent의 종류에 따라 비즈니스 로직 수행 후 State를 업데이트, 만약 View가 특정 동작을 수행해야한다면 Event를 emit 하는 흐름이다.
이 관계에서는 View → Intent → ViewModel → State/Event → View의 흐름으로 데이터가 이동하며, View와 ViewModel이 직접적으로 참조하는 불상사를 피할 수 있다.
Clean Architecture
개요
이 아티클의 정의에 따르면, Clean Architecture은 “소스 코드 자체만으로 비즈니스 로직을 명확하게 식별할 수 있는 구조”로, 의존성이 낮고 변경에 유연한 소프트웨어 개발 방법론이다.
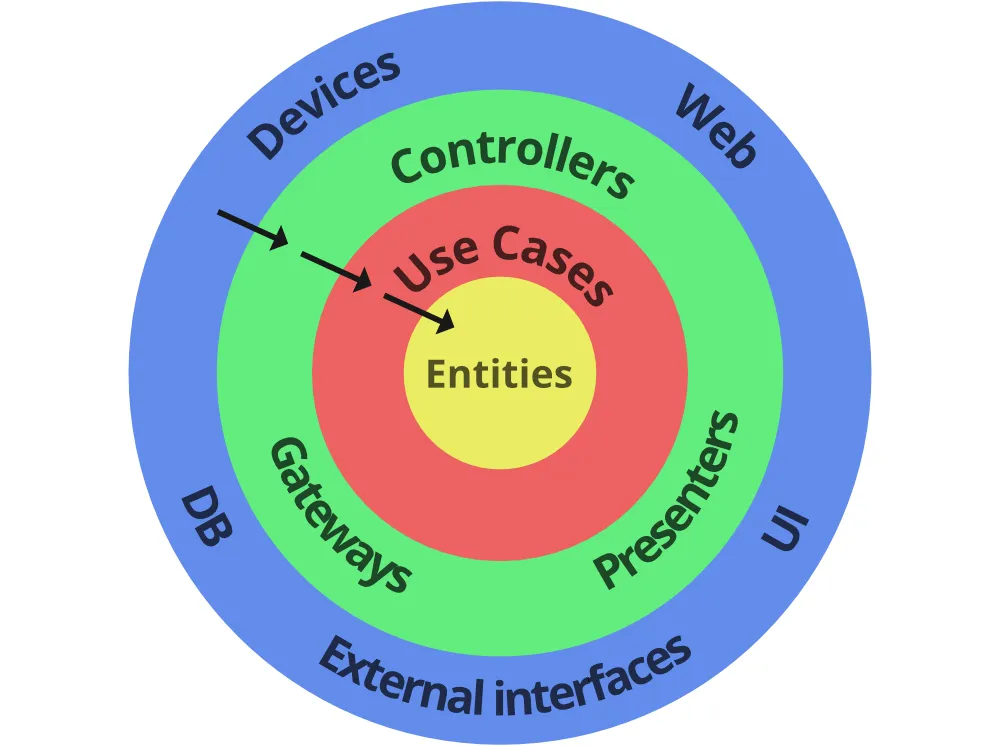
클린 아키텍처를 검색하면 항상 나오는 그 그림이다. 이 그림이 말하고자 하는 바는,
- 가운데
Entities로 갈 수록 추상적이고 Domain 영역에 가까워진다. - 의존 관계는 자신의 바로 안쪽의 레이어로만 향한다. 예를 들어,
Controllers는UseCases에만 의존한다.
안드로이드에서는..
안드로이드에서는 다음의 구조로 작업한다:
app: 모든 모듈을 아는 최상위 모듈.data: 내장 DB, 혹은 서버 등의 외부 통신을 담당하는 data source.presentation: 전통적인 View를 담당하는 UI + VM Layerdomain: 순수 Kotlin 라이브러리. 위 이미지의 “Entites & UseCases”에 집중
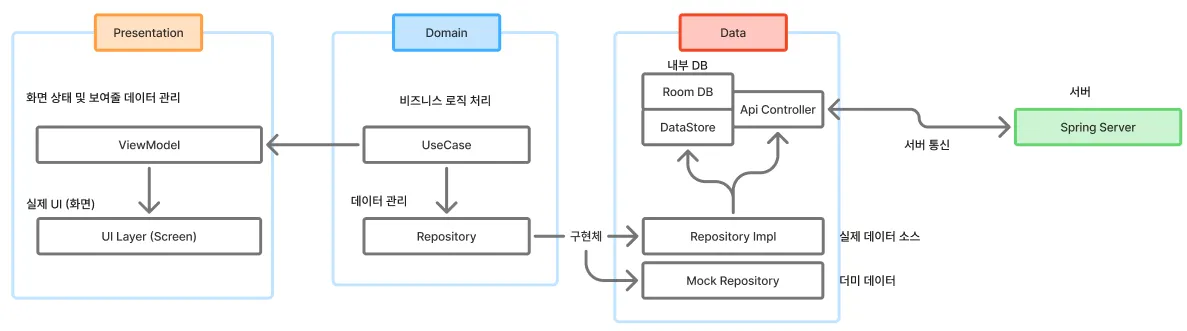
간략하게 표현하면 위 이미지와 같다. domain 레이어는 그 누구의 존재도 알지 못하며, data, presentation 레이어가 domain 레이어에 의존하는 구조이다 - 흔히들 의존성 역전 원칙이라고 부른다. 그리고 누군가는 앱의 전체적인 그림을 알아야 빌드가 가능하므로, app 모듈은 모든 레이어를 통합하는 최상위 모듈의 역할을 맡는다.
만약 저기에 외부 모듈이나 다른 엔진이 모듈/라이브러리 형태로 탑재되게 된다면 적절한 위치에 삽입되겠으나 큰 원칙은 깨지지 않을 것이다. 나보다 더 추상화된 바로 안쪽 레이어로만 의존 관계를 갖기.
왜 굳이 ‘모듈’로 분리할까?
이것도 한번쯤 생각해볼만한 주제같아서 추가해보았다. 그냥 app 모듈 내부에 package 단위로 분리하면 되는걸, 왜 굳이 모듈 단위로 구분해야하는걸까?
1. 모듈 단위 격리 테스트
특정 모듈에 대한 테스트만을 수행할 수 있으므로 유지보수가 용이하다. 예를 들어, Presentation 모듈의 UI만 수정했는데, 이를 위해 data, domain 레이어까지 굳이굳이 함께 테스트 할 필요는 없다. 적당히 mock data 넘겨줘서 잘 그려주는지 보면 되는거지.
2. 컴파일 오류로 실수 방지
동일 모듈 내에서는, 다른 패키지의 파일을 참조해도 문제가 발생하지 않는데, 이는 kotlin의 internal 키워드가 모듈 단위로만 동작하기 때문이다.
즉, 만약 app 모듈에 안드로이드 모듈에 의존하는 Presentation 레이어와 순수 Kotlin/Java 모듈인 Domain 레이어가 공존할 경우, Domain 레이에서 실수로 안드로이드에 의존하는 함수를 끌어다써도 조용히 묻힐 수 있다.
즉, 패키지 단위로 구분하는건 ‘컨벤션’이지만, 모듈 단위로 분리해두는 것은 안지키면 빌드가 안되는 ‘컴파일러 레벨의 제약’이다.
3. 빌드 효율
이건 gradle의 빌드 스크립트의 동작 원리와 관련된 내용으로, 두 가지 측면에서 생각해볼 수 있다.
우선 병렬적인 빌드 방식이다. 빌드 시 gradle은 처음에 의존성 그래프를 그리며, 하위 모듈부터 차근차근 컴파일한다. 이때, 서로 의존 관계가 없는 모듈들은 병렬적으로 컴파일 할 수 있으므로 예를들어 data 레이어와 presentation 레이어는 동시에 컴파일될 수 있다.
그리고 빌드 캐시의 측면이다 << 이 부분이 조금 더 현실적이다. 예를 들어 data 모듈만이 수정되었는데 굳이 구태여 다른 모든 모듈을 다시 빌드해야 할 이유가 있을까? 우리는 이런 비효율적인 작업을 방지하기 위해 ‘캐시’라는 것을 도입한다. 일단 한번 빌드 된 적이 있다면, 특정 모듈이 수정되어 재빌드가 발생할 수정되지 않은 부분은 기존에 빌드한 전적이 있으므로 (cache hit) 재컴파일 과정을 생략할 수 있는 것이다.
실제로 현업에서, 기존 단일 app 모듈 내에서 모든 로직을 처리하는 주먹구구식 레거시 코드를 클린 아키텍처 코드로 전환한 적이 있었다. 그 과정에서 불필요한 빌드 스크립트를 걷어내고 모듈간의 의존성 관계를 다시 맞춰준 결과, 이전에 비해 빌드 과정이 6~70%정도 빨라진 것을 확인할 수 있었다. 물론 당시 프로젝트가 결과적으로 7개의 모듈을 사용해야했으므로 눈에 띄는 효과가 있었던 것도 사실이지만, 분명한건 모듈 별 분리와 의존 관계 설정이 유의미한 영향을 미친다는 것이었다.
결론
물론 아키텍처나 특정 패턴과 제약이, 모든 상황에 적합한 만병통치약은 아니다.
하지만 아무리 AI가 발달했다 하더라도, 여전히 여러 옵션들을 테이블에 올려놓고 현재 문제에 가장 적합한 옵션을 선택하는 것은 아직까지 인간의 영역이니까. 여러 구조와 패턴을 접해보고, 내가 (혹은 AI가) 보고있는 이 프로젝트가 어떤 구조로 올라가고 있는지, 데이터의 흐름은 어떠한지 추적할 수 있는 것 자체가 더 중요한 역량이 아닐까란 생각이 들었다.
Comments